实现给一个路径,去查找test开头的测试用例文件
创建一个计算器的类,方便后面测试用
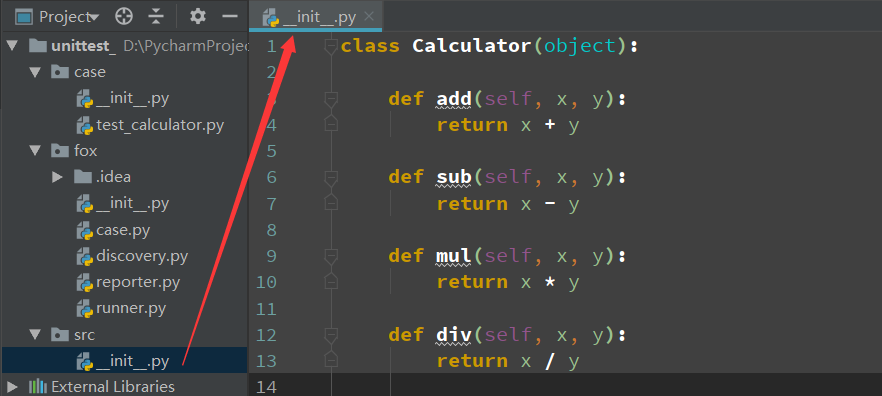
class Calculator(object): def add(self, x, y): return x + y def sub(self, x, y): return x - y def mul(self, x, y): return x * y def div(self, x, y): return x / y
创建一个unittest的用例集
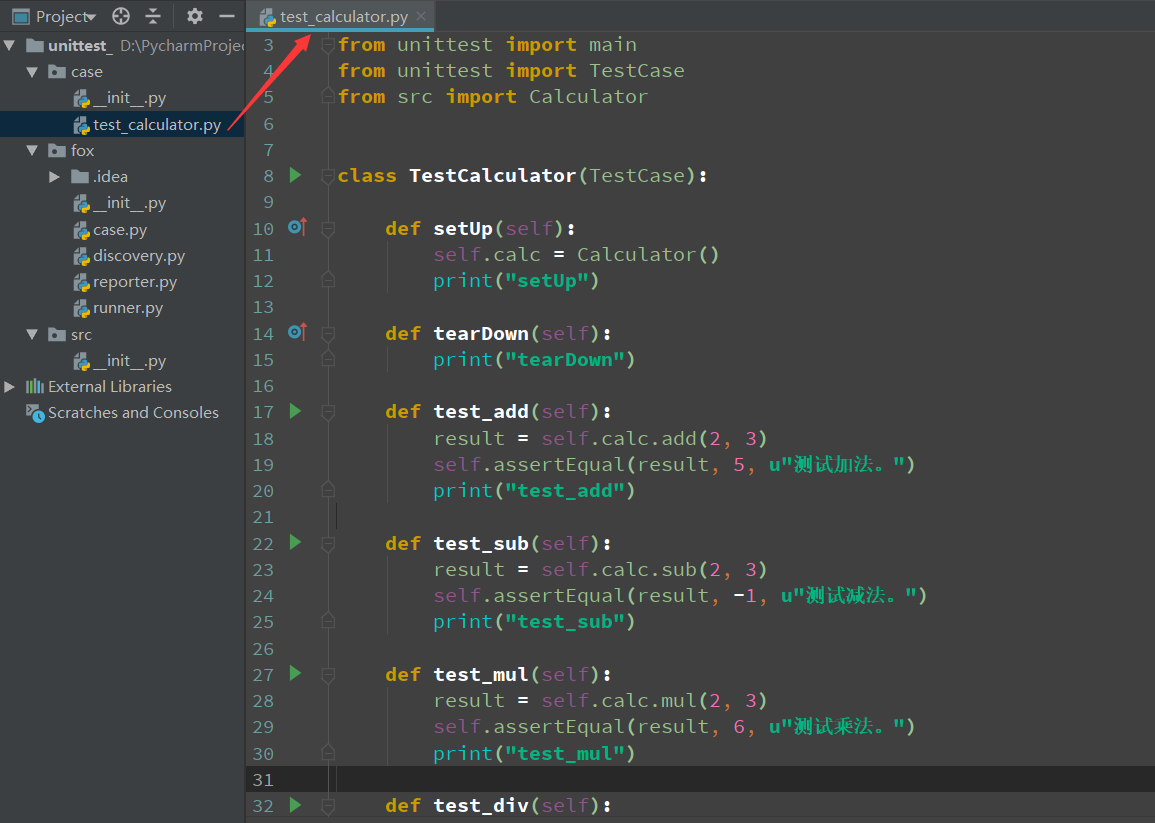
# coding=utf-8 from unittest import main from unittest import TestCase from src import Calculator class TestCalculator(TestCase): def setUp(self): self.calc = Calculator() print("setUp") def tearDown(self): print("tearDown") def test_add(self): result = self.calc.add(2, 3) self.assertEqual(result, 5, u"测试加法。") print("test_add") def test_sub(self): result = self.calc.sub(2, 3) self.assertEqual(result, -1, u"测试减法。") print("test_sub") def test_mul(self): result = self.calc.mul(2, 3) self.assertEqual(result, 6, u"测试乘法。") print("test_mul") def test_div(self): result = self.calc.div(4, 2) self.assertEqual(result, 2, u"测试除法。") print("test_div") if __name__ == '__main__': main()
查找用例的类
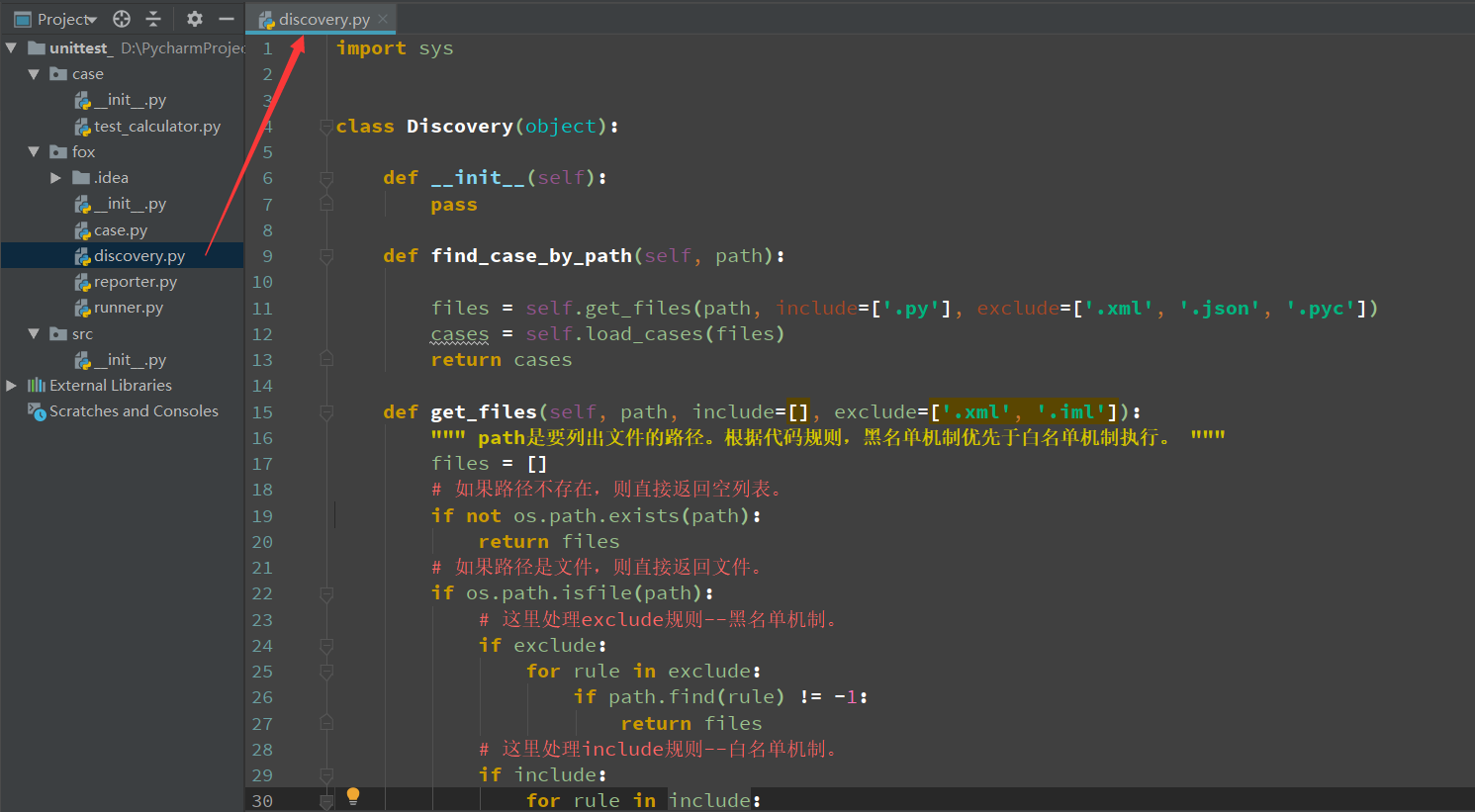
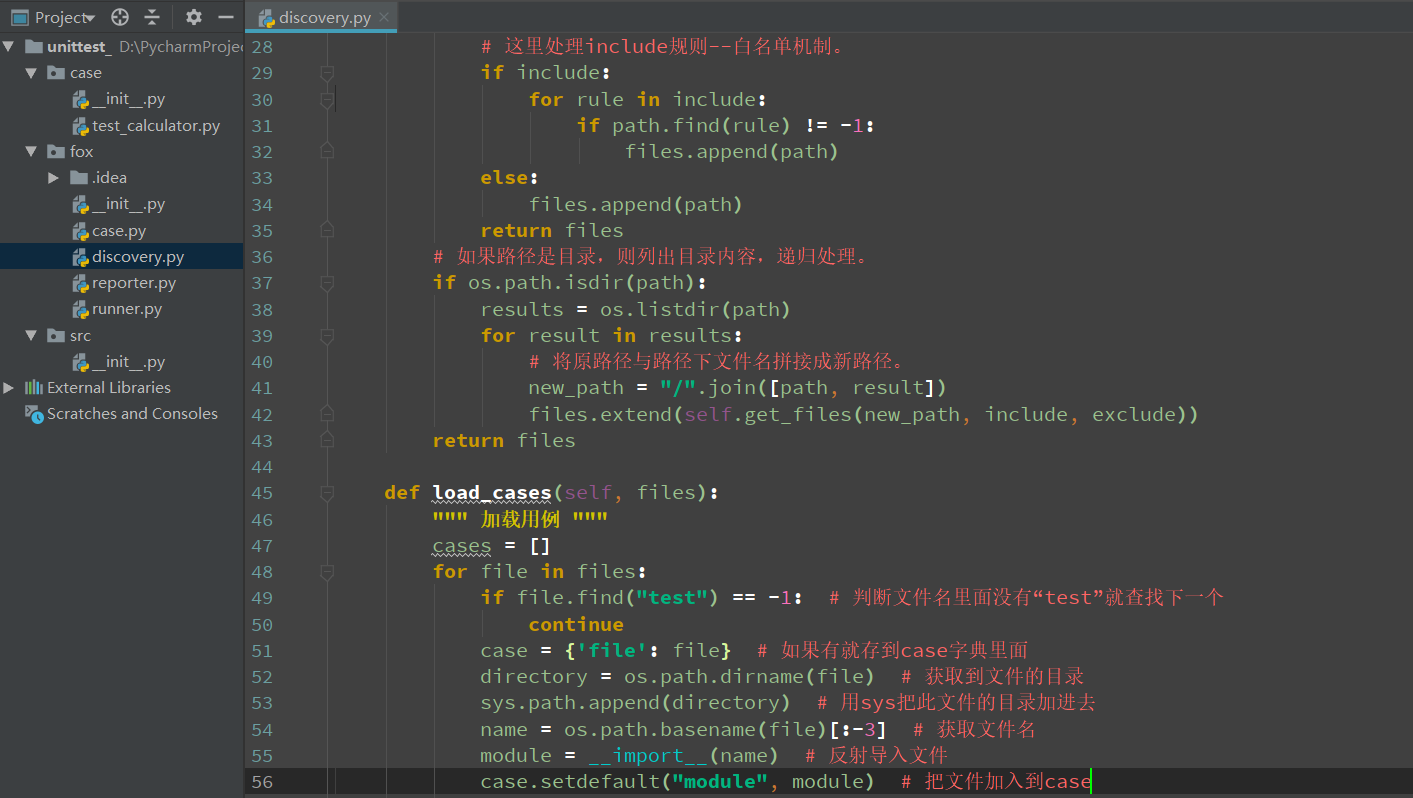

import sys class Discovery(object): def __init__(self): pass def find_case_by_path(self, path): """ 获取用例 """ files = self.get_files(path, include=['.py'], exclude=['.xml', '.json', '.pyc']) cases = self.load_cases(files) return cases def get_files(self, path, include=[], exclude=['.xml', '.iml']): """ path是要列出文件的路径。根据代码规则,黑名单机制优先于白名单机制执行。 """ files = [] # 如果路径不存在,则直接返回空列表。 if not os.path.exists(path): return files # 如果路径是文件,则直接返回文件。 if os.path.isfile(path): # 这里处理exclude规则--黑名单机制。 if exclude: for rule in exclude: if path.find(rule) != -1: return files # 这里处理include规则--白名单机制。 if include: for rule in include: if path.find(rule) != -1: files.append(path) else: files.append(path) return files # 如果路径是目录,则列出目录内容,递归处理。 if os.path.isdir(path): results = os.listdir(path) for result in results: # 将原路径与路径下文件名拼接成新路径。 new_path = "/".join([path, result]) files.extend(self.get_files(new_path, include, exclude)) return files def load_cases(self, files): """ 加载用例 """ cases = [] for file in files: if file.find("test") == -1: # 判断文件名里面没有“test”就查找下一个 continue case = {'file': file} # 如果有就存到case字典里面 directory = os.path.dirname(file) # 获取到文件的目录 sys.path.append(directory) # 用sys把此文件的目录加进去 name = os.path.basename(file)[:-3] # 获取文件名 module = __import__(name) # 反射导入文件 case.setdefault("module", module) # 把文件加入到case for attr in dir(module): if attr.find("TestCase") != -1: # 判断文件里面有没有继承了“TestCase”的类(兼容unittest) continue if attr.find("Test") == -1: # 判断类名里面有没有Test continue object = getattr(module, attr)() # 反射的方式实例化对象 case.setdefault("object", object) # 获取这个对象 case.setdefault("method", []) for attr in dir(object): # 提取测试用例里面的方法 # 这里是断言结果。 if attr.find('result') != -1: case.setdefault("result", getattr(object, attr)) if not callable(getattr(object, attr)): # 从object代表的对象获取attr代表的函数,判断是否可以调用 continue if attr.find("test") != -1: case["method"].append(getattr(object, attr)) if attr.find("setUp") != -1: case.setdefault("setUp", getattr(object, attr)) if attr.find("tearDown") != -1: case.setdefault("tearDown", getattr(object, attr)) cases.append(case) return cases if __name__ == '__main__': discovery = Discovery() import os case_path = os.path.join(os.path.dirname(os.getcwd()), 'case') # case 文件夹 print(case_path) cases = discovery.find_case_by_path(case_path) print(cases)